
O Fabric é uma solução integrada para empresas que abrange várias componentes como por exemplo Data Engineering, Data Science e Business Intelligence. O seu conjunto de serviço como por exemplo o Data Lake, permite uma integração de dados num único lugar.
No entanto tal como qualquer novidade tem sempre uma curva de aprendizagem que dependendo da experiência de cada utilizador pode ser maior ou menor.
No caso do Fabric e em específico do OneLake temos uma abordagem baseada na persona, ou seja, podemos utilizar a linguagem com que nos sentimos mais confortáveis.
Vamos focar-nos em dois artefactos específicos o data warehouse e lakehouse ambos permitem o armazenamento de informação, no entanto a forma como o fazem e as possibilidades de escrita, e leitura dos dados são diferentes:
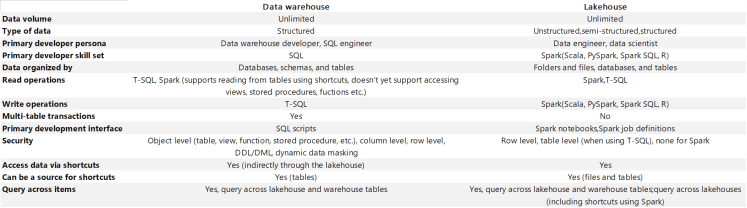
Podemos utilizar por exemplo Spark, T-SQL, Phyton, R e através do semantic link podemos inclusivamente analisar os modelos semânticos utilizando DAX.
Neste post queremos ver algumas das opções na utilização do SQL para analisarmos e modificarmos os nossos dados disponíveis em Warehouse ou Lakehouse.
Na criação de qualquer dos artefactos é automaticamente gerado um SQL Endpoint para acesso a base de dados, no entanto esta ligação funciona de forma diferenciada para os dois artefactos. Enquanto o SQL Endpoint no Lakehouse é apenas de leitura, não permitindo a alteração ou utilização de comandos para alterações da estrutura, já no Warehouse temos capacidade de escrita e leitura, tendo permissões para realizarmos todos o tipo de operações (leitura, criação de tabelas, escrita de dados, etc).
Tal como referimos o SQL endpoint é criado na mesma altura da criação da Warehouse ou da Lakehouse.
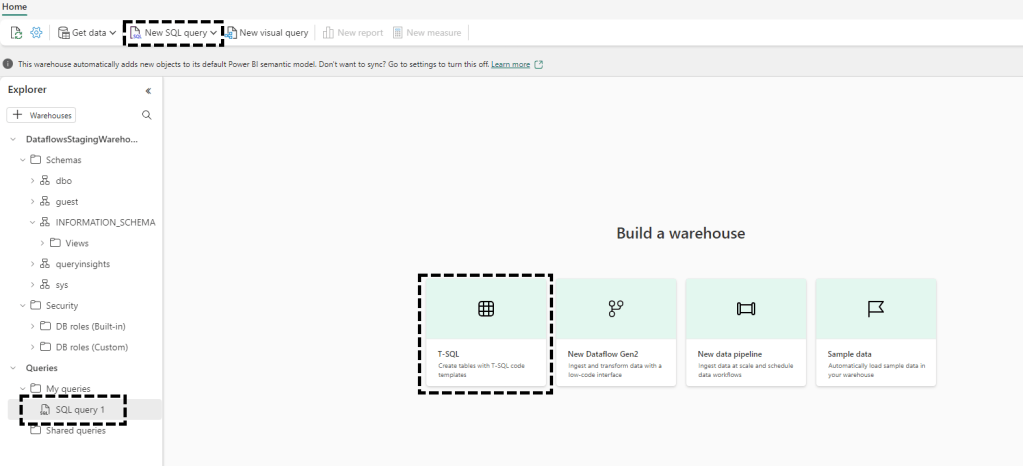
Nas imagens abaixo podemos verificar algumas das opções de acesso ao T-SQL para os dois artefactos.
Warehouse:
Lakehouse:

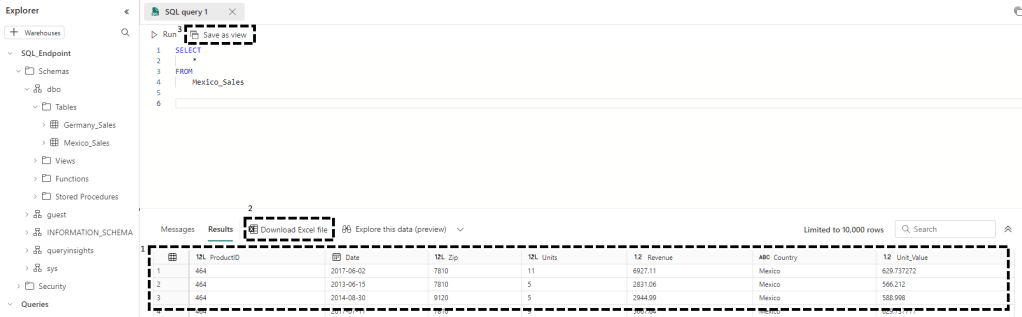
Podemos assim escrever queries mais ou menos complexas e obter o nosso resultado diretamente na janela do browser (1), exportando para um ficheiro de excel (2) ou criando uma view na nossa base de dados (3):
Uma outra forma de utilizarmos este SQL endpoint e para quem não sabe escrever SQL temos ainda a possibilidade de criar uma Visual query que tem uma aparência similar ao Power Query e que no final nos permite visualizar o SQL que foi gerado:
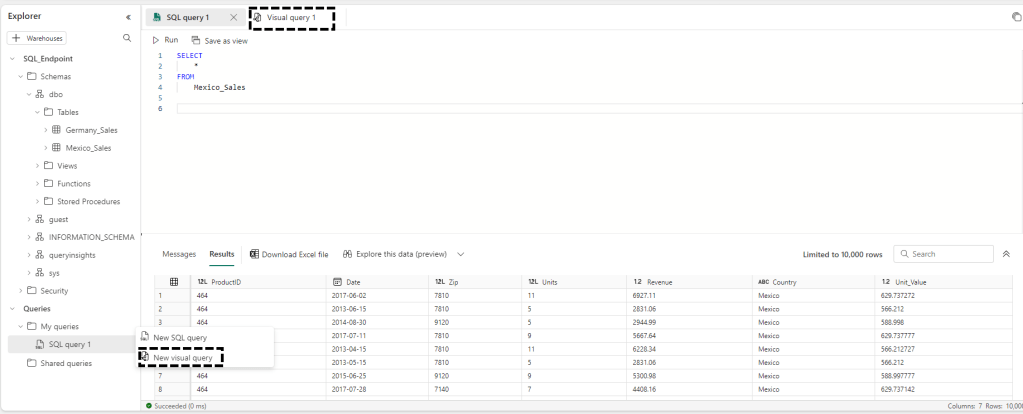
No exemplo abaixo realizamos o filtro na tabela do Mexico_Sales e alteramos o nome da coluna Country para Region e o seu valor para LATAM:

O visualizador de SQL tem o seguinte aspeto
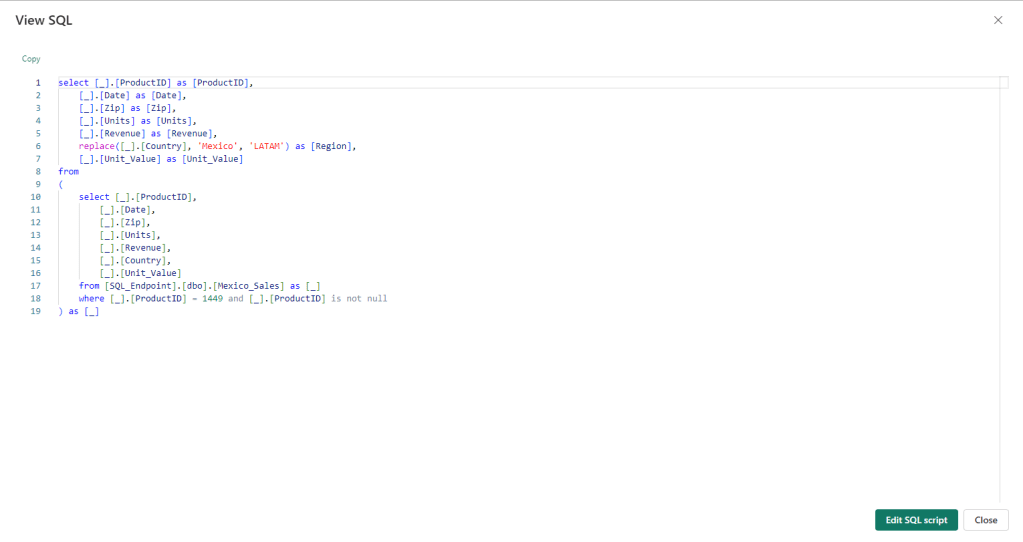
Ainda temos a possibilidade de editar o nosso script SQL na janela de edição do SQL Query:

Para finalizarmos sendo um SQL Endpoint podemos aceder ao mesmo através de qualquer ferramenta que permita ligação a servidores de SQL o SQL Server Management Studio ou o Visual Studio Code entre outras, para isso apenas temos de copiar o link do no Endpoint que está disponível no menu de contexto ou no menu de opções do lakehouse ou warehouse:
Lakehouse:

Warehouse
Tal como podemos verificar as possibilidades são várias e temos assim diversas formas de interagir com os nossos dados, seja para visualização e validação dos mesmos ou para alteração das nossas bases de dados em Fabric.
Temos no entanto algumas limitações que devemos referir (retirado do site da MSFT):
As limitações a seguir aplicam-se à análise SQL endpoint, geração automática de esquema e descoberta de metadados.
- Os dados devem estar no formato Delta Parquet para serem “descobertos” automaticamente no SQL endpoint. O Delta Lake é uma estrutura de armazenamento de código aberto que permite a construção da arquitetura Lakehouse.
- Não existe suporte para tabelas com colunas renomeadas no SQL Endpoint.
- As tabelas delta criadas fora da pasta
/tablesnão estão disponíveis no SQL Endpoint. Se uma tabela não estiver visível no Lakehouse, deverá ser verificada a localização da tabela. Somente as tabelas que estão referenciadas na pasta/tablesestão disponíveis no warehouse. As tabelas que fazem referência a dados na pasta/filesno lakehouse não estão visíveis no SQL Endpoint. Como alternativa, deverão mover os dados para a pasta/tables. - Algumas colunas que existem nas tabelas Delta do Spark podem não estar disponíveis nas tabelas no SQL Endpoint. Consulte os tipos de dados para obter uma lista completa dos tipos de dados suportados.
- Uma restrição de foreign key entre tabelas no SQL Endpoint, não permite a realização de alterações de esquema (por exemplo, adicionar novas colunas). Se as colunas com formato suportados pelo Delta Lake não estiverem visíveis no SQL Endpoint, deverá ser verificado se existe uma restrição de foreign key que possa impedir atualizações na tabela.
