
Os notebooks no Fabric permitem realizar diversas tarefas tal como ingestão, transformação, análise de dados criação de modelos machine learning, entre outras. A utilização desta funcionalidade no processamento de dados de uma organização tem associada uma grande flexibilidade, uma vez que podemos correr estes notebooks diretamente na interface do notebook, através de data pipelines ou inclusivamente dentro de outro notebook.
Os notebooks são constituídos por diversas células onde podemos correr código em diversas linguagens Apache Spark:
- PySpark (Python)
- Spark (Scala)
- Spark SQL
- SparkR
Além desta distinção entre os tipos de linguagem que podem ser definidas através da seleção na respetiva célula, também podemos utilizar a notação “%%linguagem”
Para cada célula estão disponíveis as opções apresentadas na imagem seguinte:

Devido a ser uma abordagem programática temos inerente um conceito de reutilização do código podendo incluir no mesmo variáveis que nos permitem correr as nossas linhas de código de forma recorrente sem necessidade de estarmos sempre a editar o nosso notebook.
Os parâmetros podem ser criados diretamente nas células simplesmente escrevendo o nome do mesmo e o valor por defeito (exemplo abaixo):
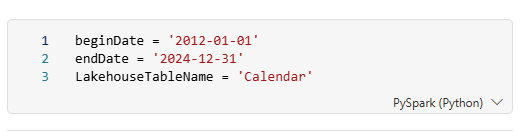
Neste caso estamos a criar 3 variáveis que nos permitem definir a nossa data de início e data de fim para a criação de uma tabela de calendário assim como o nome que vamos dar a nossa tabela no lakehouse.
De seguida podemos escrever o seguinte código:
from pyspark.sql.functions import explode, sequence, to_date
from pyspark.sql.functions import to_date, year, quarter, month, dayofmonth, date_format, weekofyear
(
spark.sql(f"select explode(sequence(to_date('{beginDate}'), to_date('{endDate}'), interval 1 day)) as calendarDate")
.createOrReplaceTempView('dates')
)df = spark.sql(f"""
CREATE OR REPLACE TABLE {LakehouseTableName}
select
CalendarDate as Date,
year(calendarDate) as Year,
case when
month(calendarDate) <4 then "Q1"
when
month(calendarDate) <7 then "Q2"
when
month(calendarDate) <10 then "Q3"
else
"Q4" end
as Quarter,
month(calendarDate) as Month_Number,
date_format(calendarDate, 'MMMM') as Month,
extract(week FROM calendarDate) Week,
date_format(calendarDate, 'EEEE') as CalendarDay,
dayofweek(calendarDate) AS WeekDay,
concat(year(calendarDate) ,"-", date_format(calendarDate, 'MM')) as Period
from
dates
order by
calendarDate """)
Neste caso e utilizando T-SQL podemos adicionar as nossas variáveis ao código utilizando a notação {variable_name}.
Isto permite que dinamicamente possamos alterar o resultado:
De modo a conseguirmos reutilizar este código noutros artefactos do nosso ambiente de Fabric temos de ativar a célula com as nossas variáveis como uma célula de parâmetros:
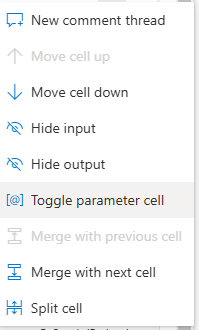

Com esta opção podemos agora correr este notebook através de outro notebook ou de um pipeline.
Notebook:
%run NotebookName {parameter1: 'parameter1value', ..., parameterN:'parameterNValue'}No nosso exemplo utilizaríamos o seguinte código:
%run CalendarCreation {beginDate: '2012-01-01', endDate: '2024-12-31', LakehouseTableName: 'TestTable'}Pipelines:
Nas definições da atividade de notebook devemos indicar o nome dos parâmetros (o mesmo que temos no notebook) o tipo e o valor a usar no pipeline:
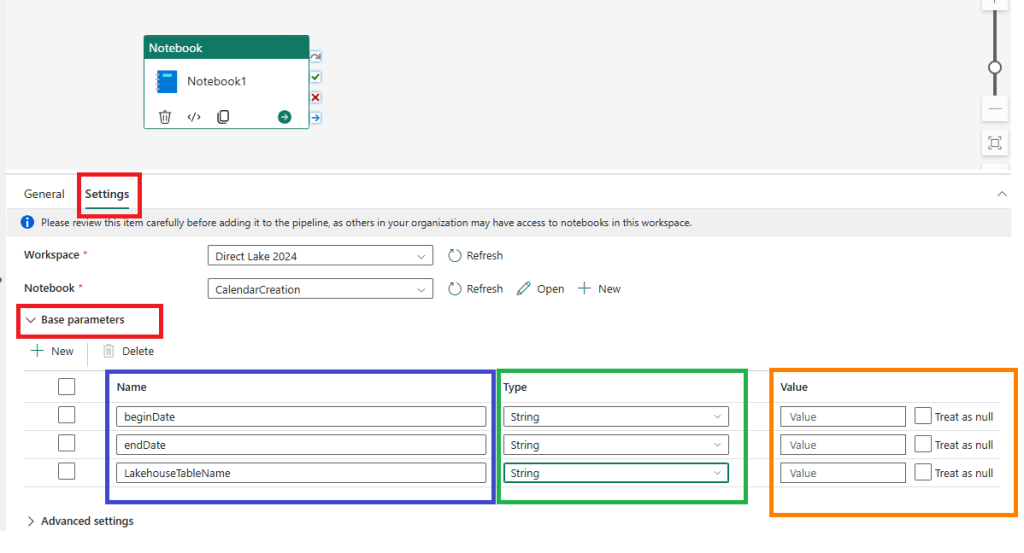
O campo dos valores poderá ser dinâmico podendo ser obtido de uma atividade de variáveis, valores de uma base de dados, ficheiros CSV, entre outros.
