
Na última semana surgiu uma questão na comunidade do Power BI sobre a possibilidade de escolher uma “frase” encontrar todas as referências noutra tabela das palavras contidas na frase escolhida.
Esta situação não é o que costuma ocorrer na maior parte dos relatórios em que o utilizador faz as seleções e o resultado retorna todos os valores que correspondem a escolha.
Ao não ser algo que fosse standard no Power BI verifiquei quais seriam as soluções feitas por outros utilizadores, sendo queda minha pesquisa com alguma criatividade na abordagem consegui através de dois post diferentes arranjar uma solução.
Nos passos abaixo encontram a solução para este problema.
Problema:
Procurar todas as palavras de forma individual de uma frase escolhida numa listagem de outras frases, não deverão ser filtradas palavras indicadas numa lista separada.
Dados:
Lista de descrições – Tabela de pesquisa

Lista de Titulos – Tabela a ser filtrada

Lista de palavras a nao incluir na pesquisa:
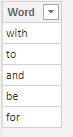
Passos:
A primeira parte do problema que identifiquei era como se podia identificar individualmente cada palavra da frase selecionada então encontrei o post abaixo:
Este blog indica-nos como podemos dividir uma frase nas suas palavras e devolver uma tabela correspondente.
Tendo então a minha frase dividida em tabela o próximo passo seria como identificar cada uma das palavras no texto final assim e recorrendo ao post abaixo tenho uma forma de encontrar uma lista de palavras de uma tabela de palavras.
Tendo as duas partes do meu problema resolvido só tinha que montar a formula assim temos a formula abaixo:
Find Word Formula =
// Character that split phrase into words
VAR SplitByCharacter = " "
// Temporary table that splits selected phrase into words
VAR Words_table =
FILTER (
ADDCOLUMNS (
GENERATE (
SELECTCOLUMNS (
ALLSELECTED ( 'Table A'[Description] );
"Find_Text"; 'Table A'[Description]
);
VAR TokenCount =
PATHLENGTH ( SUBSTITUTE ( [Find_Text]; SplitByCharacter; "|" ) )
RETURN
GENERATESERIES ( 1; TokenCount )
);
"Word"; PATHITEM ( SUBSTITUTE ( [Find_Text]; SplitByCharacter; "|" ); [Value] )
);
//Filter of words not to be searched in text
NOT ( [Word] IN VALUES ( 'Don''t filter words'[Word] ) )
)
RETURN
IF (
// Function that returns the sum of the values of the words found in the sentance
SUMX (
Words_table;
FIND (
// additonal spaces in the beginning and ending of each word allows to find the exact match, also removed the last "." so that would be specific words
" " & UPPER ( SUBSTITUTE ( [Word]; "."; "" ) ) & " ";
" " & UPPER ( SUBSTITUTE ( SELECTEDVALUE ( 'Table B'[Title] ); "."; "" ) ) & " ";
;
0
)
) > 0;
1;
BLANK ()
)O resultado final devolve uma variável de 1 se uma ou mais palavras forem encontradas no texto e vazio se não existir correspondência. Assim podemos utilizar esta medida para filtrar a nossa tabela final.

Assim como podem ver apesar de não se conseguir ter o resultado diretamente fazendo a conjugação de várias soluções é possível atingir o resultado esperado.
Leiam os blogs acima pois tem a explicação detalhada do pensamento por detrás de cada uma das soluções necessárias para resolver este problema.
